

Design & Implementation of Embedded Hardware Acceleration for Transformers
- Subject:Design & Implementation of Embedded Hardware Acceleration for Transformers
- Type:Masterarbeit
- Date:ab 04 / 2025
- Tutor:
Design & Implementation of Embedded Hardware Acceleration for Transformers
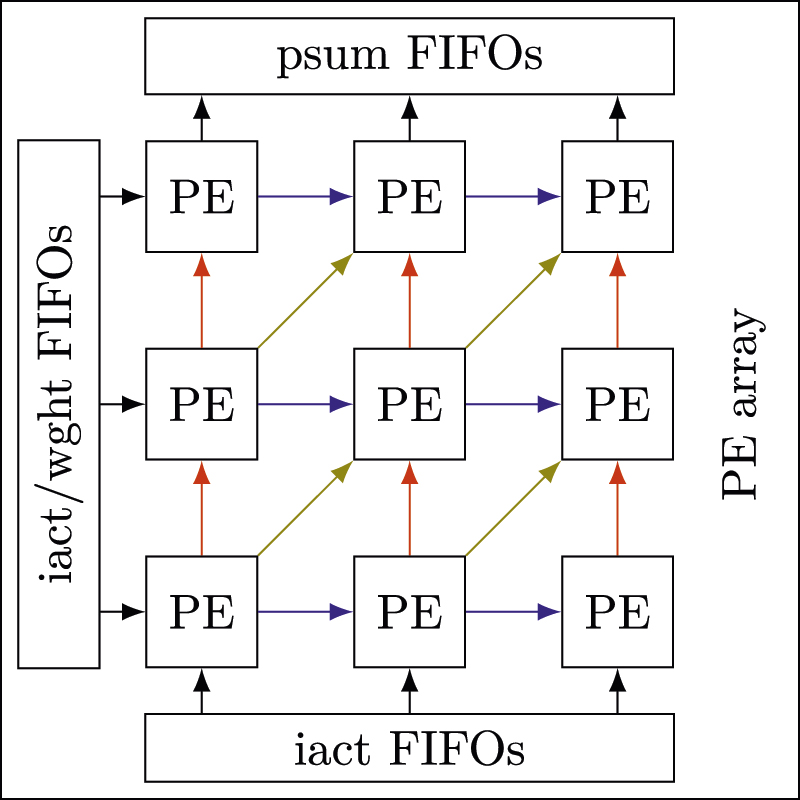
Context
Transformers are widely adopted in Natural Language Processing (e.g. chatbots and autocompletions) and Computer Vision often outperforming Convolutional Neural Networks. However, they are still a challenge for many computer systems today due to their computational complexity. FleXNNgine, ITIV's existing accelerator, so far only supports CNNs and the purpose of this master thesis is to extend its capabilities for transformers by supporting flexible matrix multiplications for self-attention mechanisms.
Targets
- In this work state-of-the-art (SOTA) of Transformer accelerators will be researched with a focus towards systolic array architectures
FleXNNgine will be extended to perform matrix multiplications
The performance of the design will be evaluated on common datasets as well as against SOTA models.
Requirements
- Interest in the design of hardware accelerators and SoCs
Knowledge of VHDL/Verilog as well as C
[1] Fabian Lesniak, Annina Gutermann, Tanja Harbaum, and Jürgen Becker. 2024. Enhanced Accelerator Design for Efficient CNN Processing with Improved Row-Stationary Dataflow. In Proceedings of the Great Lakes Symposium on VLSI 2024 (GLSVLSI '24). Association for Computing Machinery, New York, NY, USA, 151-157. https://doi.org/10.1145/3649476.3658737